
Результатом активного медиапотребления с использованием социальных сетей стали все более вопиющие случаи манипуляции мнением пользователей. Именно поэтому StopFake начинает серию публикаций об инструментах, которые позволят бороться с влиянием алгоритмов социальных сервисов на потребляемый нами контент. Мы намерено не будем предлагать нашим читателям наиболее радикальный метод – удаление профайлов в социальных сетях, ибо понимаем, что в нынешних условиях это может быть нереально. Кроме того, социальные сети являются важной платформой для работы фактчекеров, гражданских журналистов и активистов. Но мы научим вас лучше понимать, что и почему мы видим в своей ленте Facebook или Twitter (и чего не видим) и расскажем об инструментах, которые позволят максимально нивелировать влияние алгоритмов социальных сетей на отображаемый ими контент.
Cambridge Analytica и 87 миллионов жертв
Название компании Cambridge Analytica, впервые появившееся в медиа еще в 2016 году, в апреле 2018 года буквально взорвало медиапространство. Сразу в нескольких публикациях рассказывалось о том, как исследовательская компания Cambridge Analytica еще в 2015 году получила доступ к 50 миллионам профайлов пользователей социальной сети Facebook (позже стало известно, что их число на самом деле превышает 87 млн).
Часть данных была получена после того, как пользователи за деньги прошли психологический тест, созданный ученым-психологом, который и передал полученную информацию в Cambridge Analytica.
На основе данных этих профайлов компания научилась формировать и демонстрировать персонализированную рекламу, которая не только способствовала победе Дональда Трампа на выборах в США, но еще в той или иной мере повлияла на результаты более 200 избирательных процессов в разных странах мира.
Эти публикации вызвали эффект разорвавшейся бомбы. Акции Facebook обвалились, глава компании Марк Цукерберг был вызван для дачи показаний в Конгресс США. Можно по-разному оценивать и странные вопросы конгрессменов, не всегда представляющих себе, как работает Facebook и современный интернет. Но ответы Цукерберга и внимание к этой истории стали демонстрацией того, как впервые в современной истории общество (да и сам глава крупнейшей социальной сети) задумалось над тем, какое влияние Facebook и базовые принципы его работы оказывают на разные аспекты жизни, в том числе и на результаты политического волеизъявления людей во всем мире.
Facebook сообщил о целом ряде изменений, о которых мы расскажем позже. И пока будут происходить дальнейшие расследования и исследования влияния Facebook, обычным пользователям стоит задуматься о своей Facebook-зависимости и над тем, как сильно влияет Facebook и его дочерние проекты на наше медиапотребление.
Жертвы Cambridge Analytica
Первым, что предложил Facebook после публикаций истории с Cambridge Analytica, стала возможность проверить себя – не стали ли вы жертвами компании Cambridge Analytica и ее приложения, которое получило несанкционированный доступ к данным.
Чтобы выполнить эту проверку, нужно воспользоваться вот этой ссылкой.
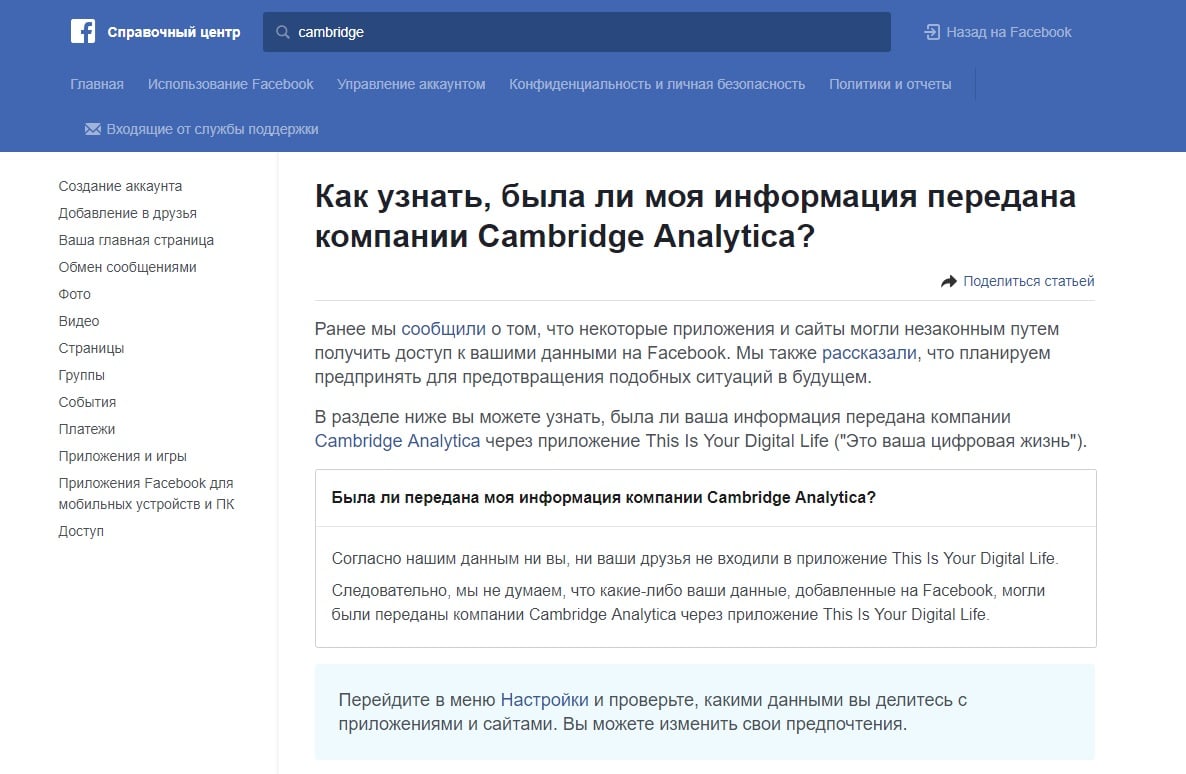
На соответствующей странице справочного раздела Facebook можно найти ответ о том, связаны ли вы и ваши друзья с приложениями Cambridge Analytica, а также предложение проверить настройки своего Facebook-аккаунта и подключенных к нему приложений.
Для этого можно воспользоваться либо ссылкой на странице помощи либо перейти в настройки своего Facebook-акаунта, а там – в раздел приложений.
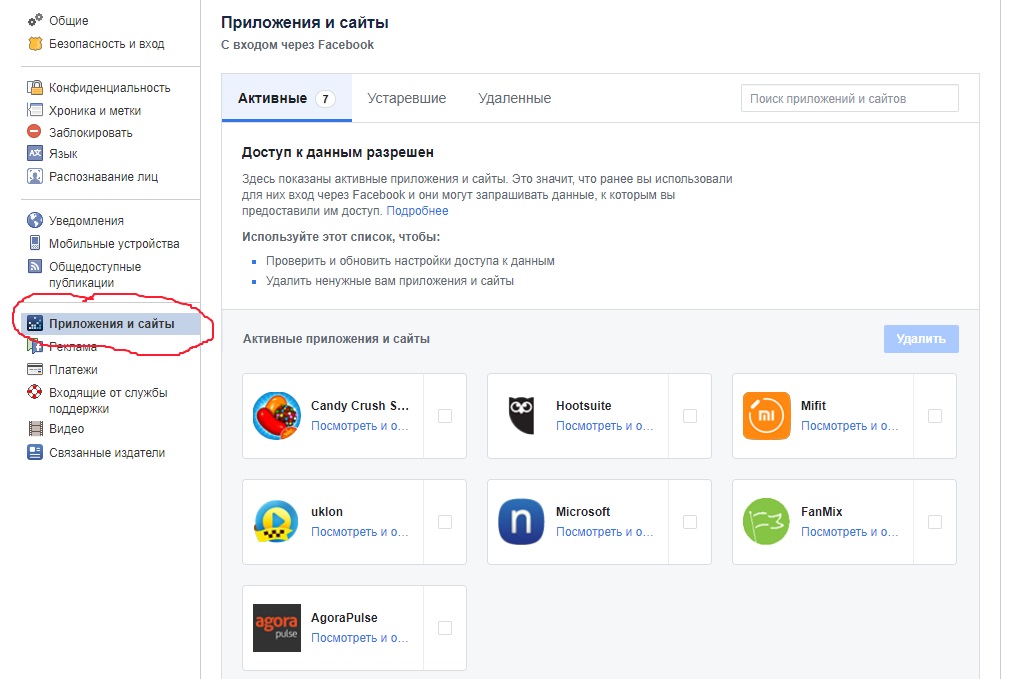
Если на этой странице вы увидите странные приложения, либо незнакомые, либо редко используемые — их лучше сразу удалить.
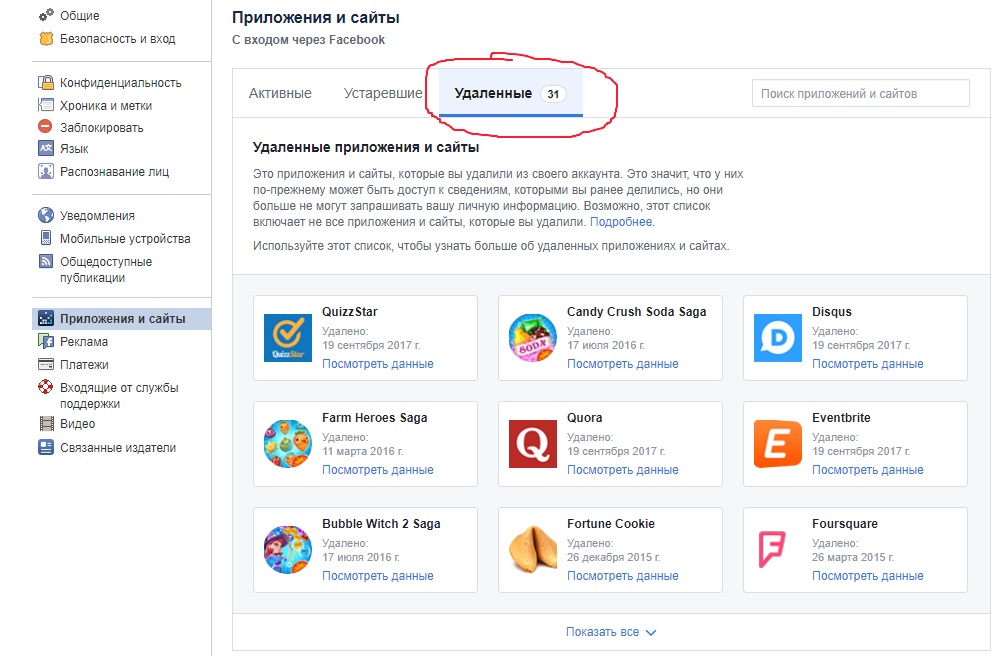
В Facebook подчеркивают, что опасными могут быть и ранее удаленные приложения. Их тоже стоит проверить.
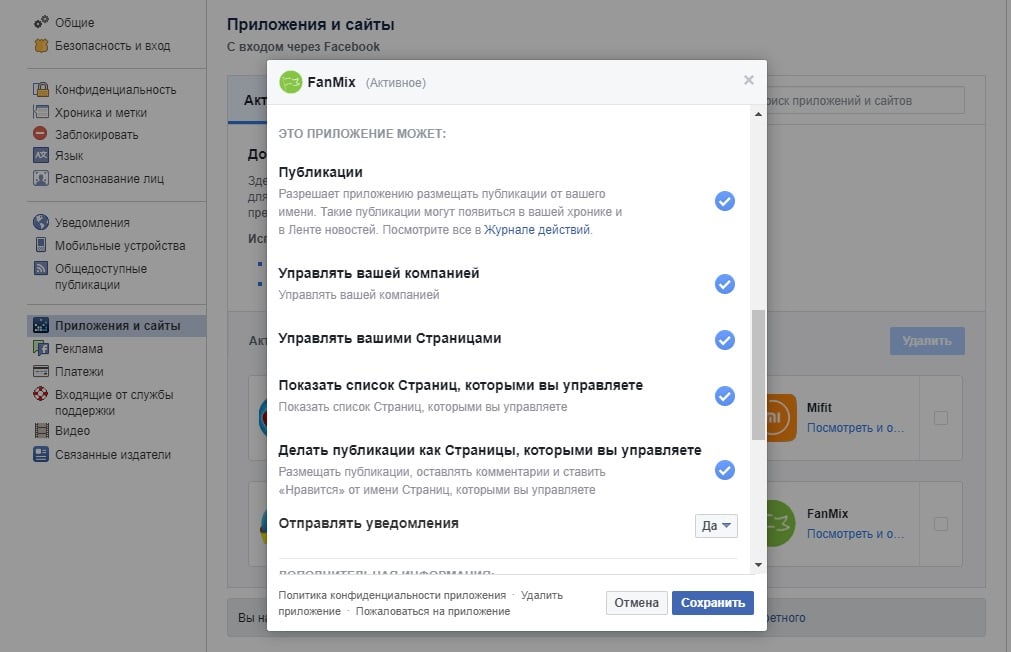
Для каждого приложения можно увидеть, какие именно разрешения у него есть и какие действия приложение может осуществлять. Если у какого-то приложения окажется слишком много прав, стоит удалить и их – сделать это можно с помощью кнопок в окне настроек.
Полезный или манипулятивный? Что и почему мы видим в соцсетях
Социальные сети хранят очень много информации о своих пользователях и используют эти данные для демонстрации рекламы. По сути бизнес-модель социальных сервисов построена на том, что они продают данные о пользователях рекламодателям, чтобы те показывали таргетированную рекламу – такую, которая будет интересна конкретному пользователю. Благодаря такой модели молодая мама видит рекламу подгузников и магазинов детской одежды, человек, интересующийся спортом – рекламу марафонских забегов и спортивного питания, а выпускник школы – рекламу университетов и курсов по подготовке к ВНО (ЗНО).
Проблема в том, что кроме информации, которую мы сами «отдаем» Facebook, заполняя свой профайл или указывая посещаемые города и мероприятия, алгоритмы социальной сети научились анализировать наши профайлы и наши действия – как внутри социальной сети, так и вне ее. И в результате это привело к тому, что Facebook знает около сотни характеристик своих пользователей, на основе которых она может показывать рекламу. Среди этих характеристик – даже такие странные как предпочитаемый стиль отдыха, наличие и тип автомобиля, использование скидочных купонов и число кредитных карт.
Социальные сети умеют собирать информацию о действиях пользователей не только непосредственно на их страницах, но и на других сайтах. Этому способствуют такие механизмы как cookies-файлы, Facebook Pixel, авторизация на сайтах через соцсети. В результате этого соцсети не только демонстрируют своим пользователям интересующий их контент. Некоторые медиа уже умеют настраивать свои главные страницы в зависимости от интересов и потребностей пользователей. Таким образом, мы сталкиваемся с более глобальным проявлением «пузыря фильтров», но не в отношении поисковых результатов, а относительно контента социальных сетей и онлай-медиа.
Facebook Container от Mozilla
Чтобы получить максимально независимый контент, для чтения новостей можно воспользоваться отдельным браузером, в котором не нужно авторизоваться в соцсетях.
Еще один способ решить эту задачу – установить совершенно новый плагин Facebook Container, созданный командой разработчиков из компании Mozilla. Плагин пока существует только для браузера Firefox. Он появился совсем недавно, возможно- как ответ на историю с Cambridge Analytica. Задача плагина – максимально усложнить для социальных сетей отслеживание онлайн-поведения человека на внешних сайтах. Иными словами, Facebook Container препятствует слежке за пользователем со стороны социальных сетей, а значит способствует более независимому медиапотреблению человека.
Facebook Container создает условный контейнер для работы в Facebook. У этого контейнера используются собственные cookies-файлы. Эти cookies-файлы не передаются вне Facebook, а значит соцсеть не может «видеть», что делает пользователь на других сайтах. А другие сайты не могут распознать своих посетителей как Facebook-пользователей
После установки Facebook Container в браузер Firefox рядом с адресной строкой при просмотре Facebook-ленты либо Facebook-страниц будет отображена специальная голубая пометка («Контейнер»). Все остальные просматриваемые страницы будут загружаться вне контейнера. Таким способом Facebook Container моделирует ситуацию, в которой Facebook и остальные сайты будто бы используются в разных браузерах.
Правда, нужно понимать, что другие рекламные сети — та же реклама от Google — может пытаться идентифицировать пользователя и «подсовывать» ему интересующий его контент.
Как избавиться от курирования контента или Вспомним о RSS
Алгоритмические ленты Facebook и других сервисов стали одним из вариантов проявления курирования контента – отбора и предоставления контента в удобном и интересном для пользователя виде. Появление понятия курирования контента связано с огромным количеством записей в соцсетях, невозможностью следить и воспринимать их все и, конечно же, желанием компаний, владеющих соцсетями, зарабатывать на пользовательских предпочтениях.
Благодаря курированию контента (используемому не только в соцсетях, но и в некоторых онлайн-медиа) обычная лента новостей, сформированная в обратном хронологическом порядке, осталась в прошлом.
С одной стороны, курирование контента призвано сделать наше медиапотребление более удобным, с другой – мы платим за это нашими персональными данными и «делегированным» выбором того, что мы видим на своих экранах.
История с Cambridge Analytica может стать хорошим поводом вспомнить о формате RSS и инструментах чтения новостей через RSS. Этот способ потребления контента был популярным в 2008-2012 годах. Но появление Facebook и закрытие сервиса Google Reader привели к массовому отказу от работы с RSS-форматом и чтения новостей через Facebook.
Однако RSS-формат как раз и исключает все недостатки потребления новостей через Facebook – он не собирает пользовательские данные и не настраивает контент, который видят пользователи. Более того, специальные инструменты для чтения RSS умеют собрать на одной веб-странице записи из всех источников, которые нужны пользователю, сгруппировать их в категории и просматривать, как минимум, заголовки, либо полные тексты новостей. Благодаря RSS-ридерам не нужно открывать каждую отдельную страницу, чтобы прочитать новости, мириться с рекламными баннерами и всплывающими сообщениями.
RSS расшифровывается по-разному – это и RDF Site Summary, и Really Simple Syndication, и Rich Site Summary. Иными словами, RSS можно перевести как «исключительно простая синдикация». Термин «синдикация» обозначает многократную публикацию новости или статьи в нескольких источниках.
Читать RSS можно на специальных сайтах, с помощью специальных программ, называемых еще агрегаторами, или онлайновых сервисов для чтения RSS.
У формата RSS есть недостатки – чтобы таким способом можно было читать новости, нужно, чтобы сайт предлагал этот формат. Узнать, есть ли у сайта RSS-фид и можно ли читать его новости через RSS помогут специальные онлайн-сервисы – RSS-агрегаторы.
Вот несколько таких сервисов: Veen Reader, Feedly https://feedly.com , The old reader
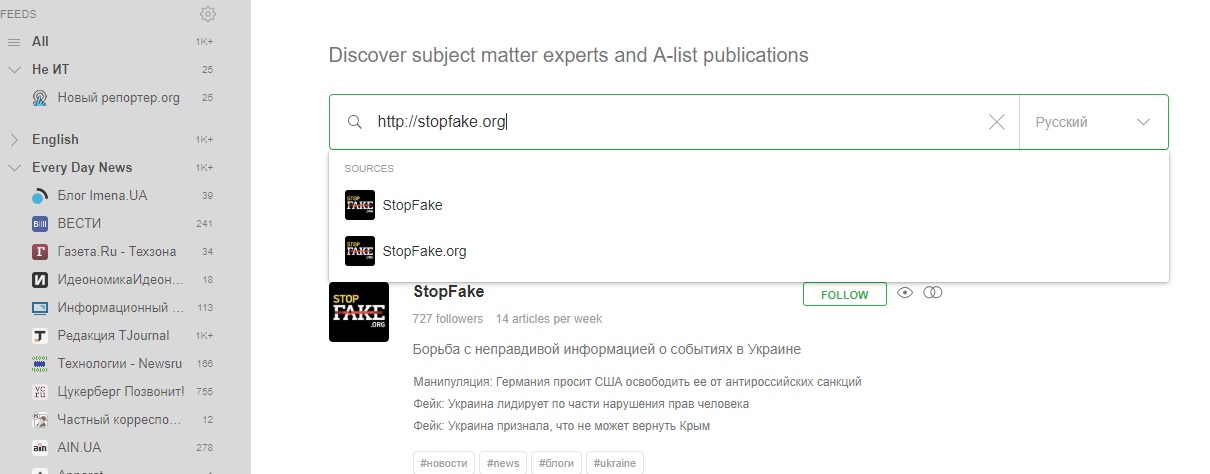
Например чтобы добавить сайт для чтения в сервис Feedly, нужно воспользоваться кнопкой Add Content, выбрать пункт Publications & Blogs и указать адрес сайта. Если у сайта есть RSS-фид, сервис Feedly предложит добавить его в свой список чтения.
В следующих публикациях раздела «Инструменты» мы расскажем о других сервисах и плагинах, задача которых – избавиться от влияния алгоритмов соцсетей на то, что и как мы читаем онлайн.
Автор: Надежда Баловсяк, для Stopfake.org.


